背景
作为一名测试,对自己写的代码就更加需要保障质量了😂。。。但又不可能每次和业务一样,每次改动后都通过手工测试去覆盖,此时便想到了单测/接口来保障测试自己开发的功能。
但现在互联网公司,不管是开发还是测试的代码的单测覆盖率普遍不高,或者说编写单测不是一个普遍的现象。 具体原因可以先来查看一段代码,实现的功能是:在指定的 Jenkins server 上根据用户自定义的参数来构建指定的Job任务,代码的格式如下:
1 | def start_job(cls, job_name, server=None, params=None): |
大致一看这块代码也没什么问题(忽略参数校验),但实际需要进行调试或者单测的时候就存在两个比较明显的问题:
- else 后面执行的代码,场景不好构建,需要Mock部分外部依赖,如:
cls.get_job_status(job_name, server)、cls.check_task_status(job_name, server); - 为了避免真实的去执行指定的Job,需要Mock
server.build_job(job_name, parameters=params);
这还仅仅是一个10行不到的代码,就需要写这么多Mock。想想那些真实的业务场景,这得多痛苦╮(╯Д╰)╭ 。。。(猜测这也是大部分公司不写单测的原因吧。)
那如何在不通过编写过多的Mock的情况下,来快速有效的对自己的代码进行调试以及编写单测呢?个人通过函数式编程找到了看似有效的一种思路。先简单的介绍下一一函数式编程(可参考:Python 函数式编程)。
函数式编程
通常编程语言支持通过以下几种方式来解构具体问题:
面向过程
比如要实现面向过程的设计思路就是首先分析问题的步骤:1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。把上面每个步骤用分别的函数来实现,问题就解决了。面向对象
在日常生活或编程中,简单的问题可以用面向过程的思路来解决,直接有效,但是当问题的规模变得更大时,用面向过程的思想是远远不够的。此时就需要通过面相对象来进行抽象和封装。面向对象可以简单的理解:万物皆对象😂。。。把要解决的问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个对象在整个解决问题的步骤中的属性和行为。
面向切面 (JAVA中的AOP和Python中的装饰器)等等。
函数式 编程则将一个问题分解成一系列函数,可以理解属于面向过程编程。 理想情况下,函数只接受输入并输出结果,对一个给定的输入也不会有影响输出的内部状态。
在大型程序中(普遍方式是:面相对象),然而在程序内部,不同的部分可能会采用不同的方式编写;比如 处理逻辑则是面向过程、日志打印以及权限控制等则是面向切面等。
⚠️ 注意:上述内容写的比较简略,未看懂也没关系,只是简单的引入了相关的概念,有兴趣的可自行阅读。
理想情况
最容易理解最容易编写的单测,莫过于独立函数的单测。所谓独立函数,就是只依赖于传入的参数,不修改任何外部状态的函数。指定输入,就能确定地输出相应的结果。运行任意次,都是一样的。在函数式编程中,有一个特别的术语:“引用透明性”,也就是说,可以使用函数的返回值彻底地替代函数调用本身。独立函数常见于工具类及工具方法。
函数式编程的核心在于:每个函数的输出必须只依赖于输入,输入如果是固定的那么输出一定是固定的。
函数式风格有其理论和实践上的优点:
模块化。
它强制你把问题分解成小的方面。因此程序会更加模块化。相对于一个进行了复杂变换的大型函数,一个小的函数更明确,更易于编写, 也更易于阅读和检查错误。组合性。
易于调试和测试。
调试很简单是因为函数通常都很小而且清晰明确。当程序无法工作的时候,每个函数都是一个可以检查数据是否正确的接入点。你可以通过查看中间输入和输出迅速找到出错的函数。测试更容易是因为每个函数都是单元测试的潜在目标。在执行测试前,函数并不依赖于需要重现的系统状态;相反,你只需要给出正确的输入,然后检查输出是否和期望的结果一致。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量(没有使用不固定的局部变量或者修改全局变量),因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
1 | # 理想情况下的独立代码如下: |
现实
现实常常没有这么美好。应用要读取外部配置,要依赖外部服务获取数据进行处理等(就如同上述代码中的 c = random.randint(1, 19) ,c是不可控的),导致应用似乎无法单纯地 “通过固定输入得到固定输出“。
导致这个现象的原因:
- 轻率地引用外部实例变量或状态或函数,使得本来纯粹的函数或方法变得不那么”纯粹“了;
- 函数的功能不够单一(比如一个求和的方法,里面还有各种其他与求和不太相关的代码存在);
- 其他因素等。
解决方案
通过吸取函数式编程中的概念,提取出如下两个点来优化函数的实现:
- 函数内引用外部依赖的函数的返回值时, 将外部函数转化为函数参数; 函数内引用外部依赖的函数,将外部函数转化为函数参数。
- 尽可能的拆分每个函数为一个比较单独的函数。
比如文章最初的Demo代码,可以进行如下的改造:
1 | # 原代码 |
具体的改动点如下:
cls.get_job_status(job_name, server)和cls.check_task_status(job_name, server)优化成函数变量。
该函数是去获取指定Job的执行状态,只会返回True/False,完全可以通过将外部变量转化为函数参数来解决。这样就可以通过函数参数直接控制 True/False 的状态,避免去构造一个真实的Job执行或未执行的场景。同理
cls.check_task_status(job_name, server)需要构建Job在Jenkins的队列中,这样实际场景中更加难以构建。通过优化成函数变量后极大的降低了构建的难度。server.build_job(job_name, parameters=params)优化为函数变量。
该函数一定会去进行真实的触发Job,所以在跑单测的时候,需要mock处理。该接口存在如下场景:- 函数执行成功,代码继续往下执行;(对被测函数
start_job无影响) - 函数执行失败,内部抛出异常或者错误信息;(被测函数
start_job只需继续往上抛异常即可,也无影响)
所以也可以将该函数直接作为一个参数传给被测函数。
1
2
3
4
5def start_job(cls, job_name, start_job_func, params=None, status=False, task_queue_status=False):
...
if not status and task_queue_status:
start_job_func(job_name, parameters=params)
...通过如上的改动,在单测代码中就可以直接定义一个假的
start_job_func不做任何操作/抛出异常, 然后进行断言后面的代码或者抛出异常的场景即可。- 函数执行成功,代码继续往下执行;(对被测函数
由于Demo代码的行数比较少,并且逻辑相对单一,此处就未进行函数拆分。但对于大部分的业务代码,实际都可以进行更小的拆分,去保障每个函数的功能单一。
最终的改造代码的效果:
- 利一一单测以及其他方法组合和调试都很方便,仅需要通过变量直接来控制逻辑条件的执行。
- 弊一一其他方法来调用的时候需要传递很多的变量(当然可以通过再次拆分,将该方法更加的细化)。
当然这块在 “纯粹” 的函数式编程以及平常的过程式/面向对象编程等其他方式中是可以进行一定的取舍的。比如已经有一个更小的函数A符合输入固定,并且输出固定, 那么在代码量没有明显增加以及不破坏函数的单一性的情况下,函数B去引用A的时候则无需将其进行参数化。
Pytest-cov 代码覆盖率工具
通过上述的方法去优化了部分核心代码后,在编写单测用例的时候也简单很多。 此处使用的覆盖率统计工具是 Pytest-cov。常用的参数如下(通过创建一个python脚本来执行对应的覆盖代码):
1 | import pytest |
- --cov:需要统计覆盖率的文件目录(可指定多个);
- --cov-config:用户自定义的配置文件;
- --cov-report:覆盖率报告生成的格式,此处选择html格式,并且存储在名为cov_html的文件夹下;
- --cov-branch:开启分支覆盖率统计(默认关闭);
更多内容可参考:Pytest-cov 官网文档,实际使用后的效果如下:
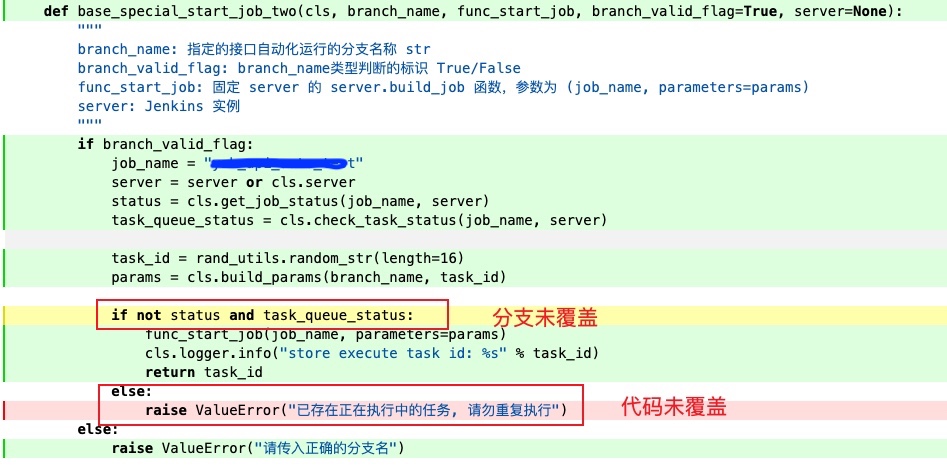
总结
该方法并不能永久的解决编写单测的难度,但是从个人实践下来的最终效果,几乎满足了80%的场景的单测覆盖度(唯一的缺点就是:需要像上面代码中去描述较多的参数)。如有其他更好的办法欢迎。